Golang基础--一篇文章记住slice的注意点
本文主要深入探讨了golang的切片基础内容。阅读本篇文章后,你将对切片有更深刻的理解,并能记住在使用切片过程中需注意的要点。
golang的切片用法基本和数组一致,可以根据下标存取数据,也可以通过遍历获取里面的所有的数据。但是它也有自己特有的用法和性质。本文的目的是通过更深层次理解切片,从而用好切片。
重要特性
- 切片就是一块可复用的内存区域 + 一个三元组(pointer,len,cap)(切片的本质)。
- 切片中能取出多少数,取决于切片的长度,能放多少数,取决于切片的容量。
- 切片如果容量足够,则不会新建一个底层数组,仍会用原来的底层数组,这时候就会影响到共用底层数组的其他切片。
切片的内部表示
切片是基于数组实现的,它的理念跟动态数组差不多。但是切片并不是动态数组,更不是一个数组指针。它比数组指针更好用,比如在传参的时候无需传递指针或者数组的拷贝便可以读取数组以及修改数组。先看下底层结构:
1type slice struct {
2 array unsafe.Pointer
3 len int
4 cap int
5}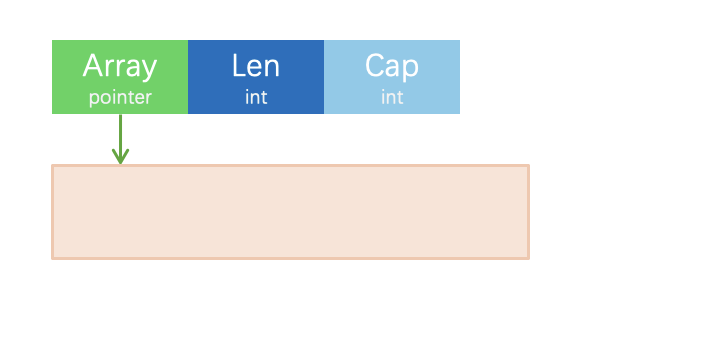
1var s []int
2sliceHeader := (*reflect.SliceHeader)((unsafe.Pointer(&s)))
3sliceHeader.Cap = length
4sliceHeader.Len = length
5sliceHeader.Data = uintptr(ptr)切片的声明和初始化
切片的声明样式和普通变量的声明一样,可以在这里看到golang的不同声明形式,但是切片的初始化方式有好几种。这里会逐一介绍这几种初始化方式,读者可以结合图片来感受len和cap的变化。
1.字面量初始化
1s := []int{1,2,3}
2var s = []int{1,2,3}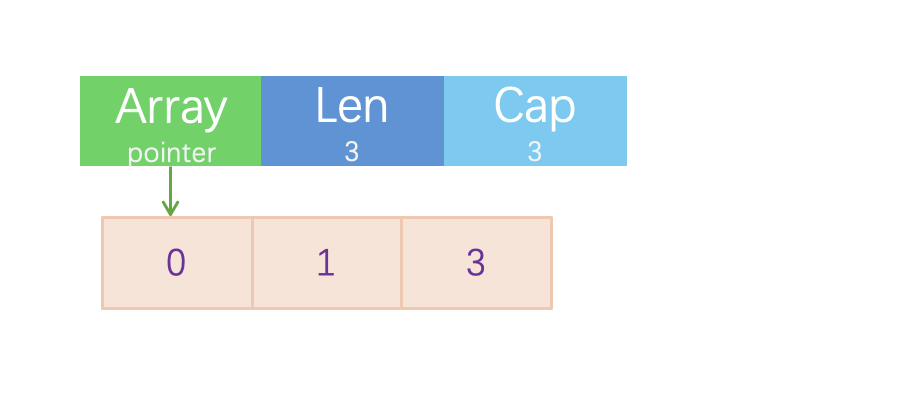
1slice:=[]int{1:1}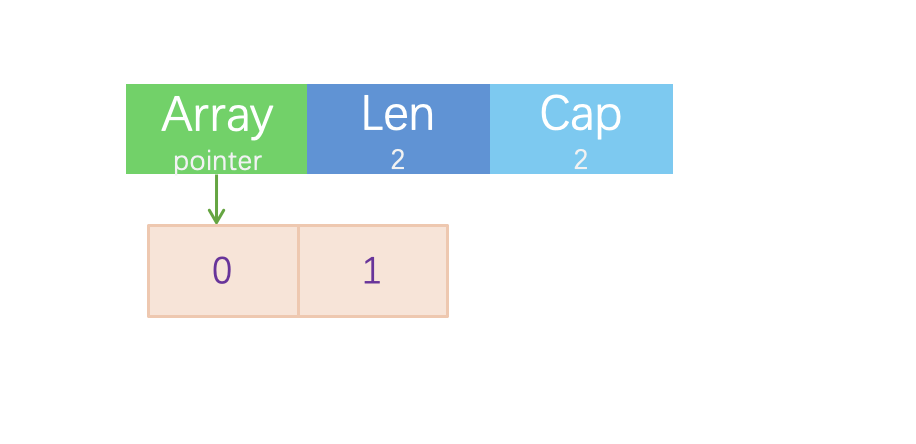
2.make初始化
slice的make初始化也有两种形式:
1s := make([]int,3)
2s := make([]int,3,6)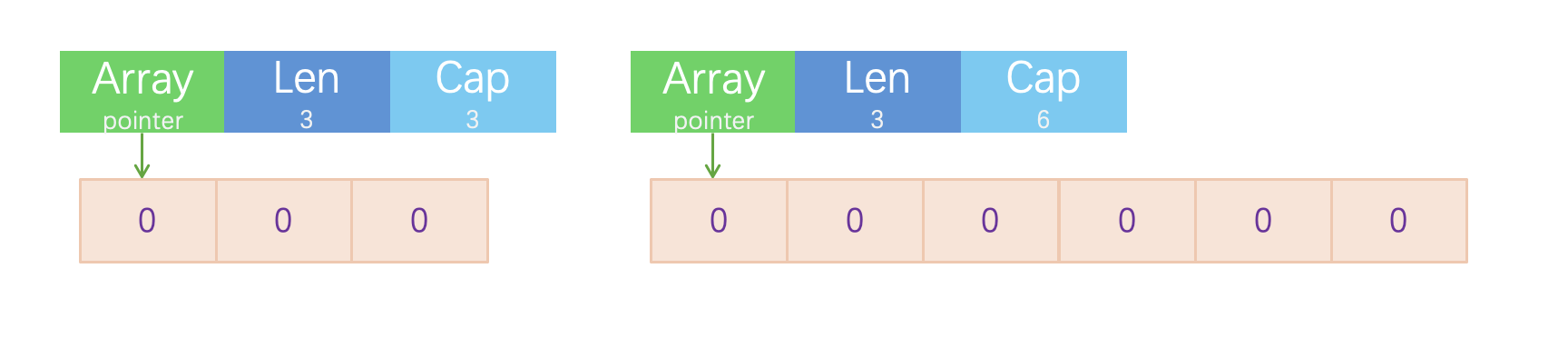
1make([]type, len, cap)3.在其他数组/切片的基础上声明和初始化切片
这种初始化方式,笔者认为是最能说明切片本质的一种形式,如果能理解这种初始化形式,可以算彻底了解了切片。
1s1 := []int{1,2,3,4,5,6}
2s2 := s1[1:2:3]1s := slice[i:j:k]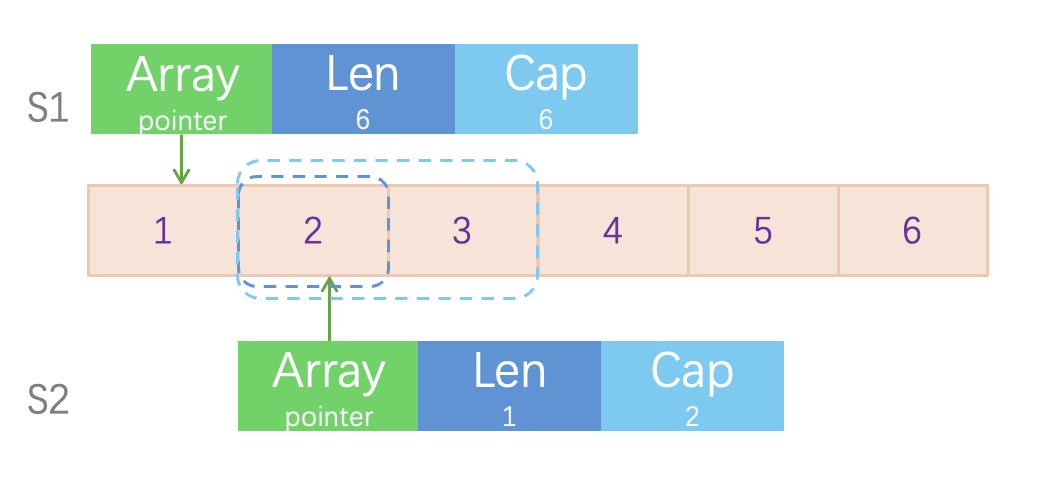
1s1 := []int{1,2,3,4,5,6}
2s2 := s1[1:2:3]
3s3 := s1[1:3:5]
4s4 := s1[2:3:5]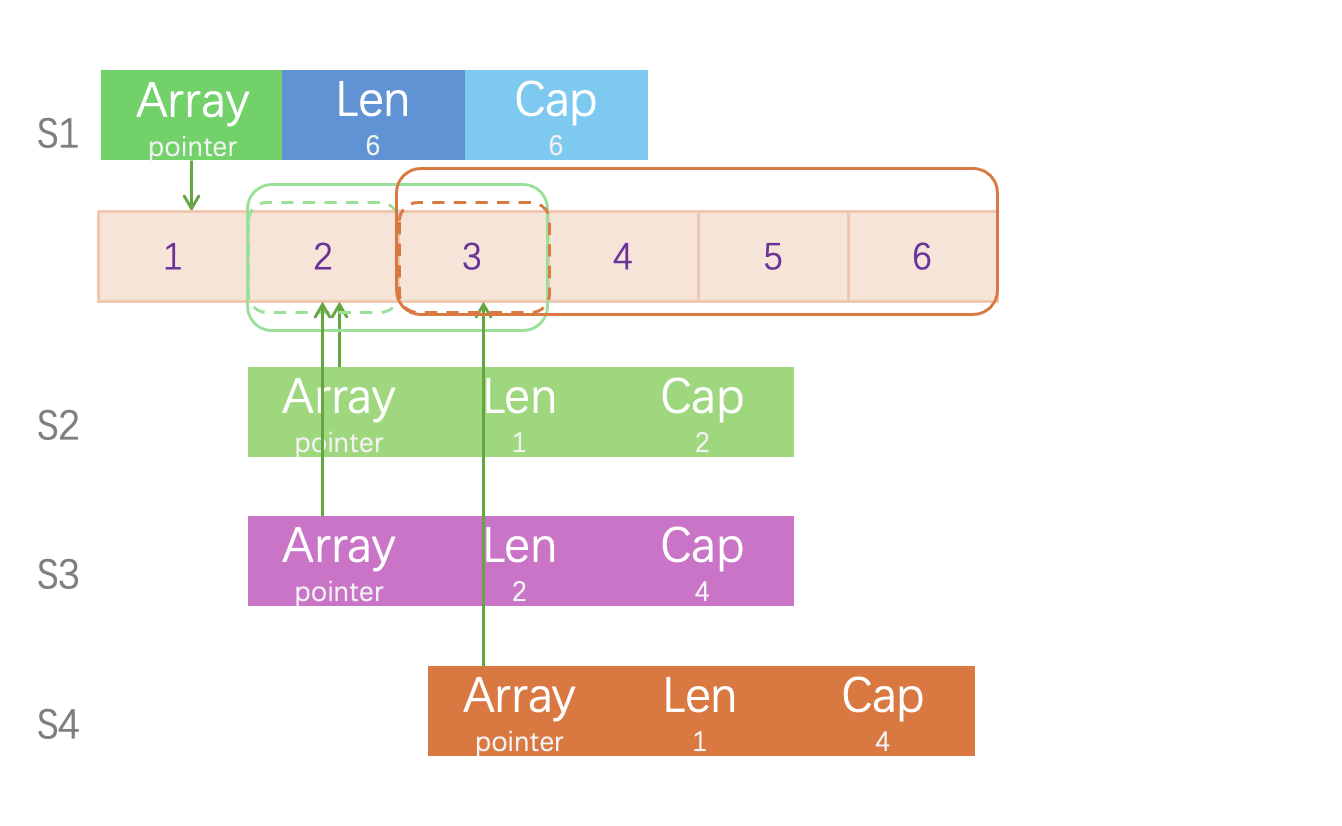
从这里也可以看出切片是灵活的,它有三个元素可以去表示它。同我们上面使用的初始化一样,我们也可以不指定容量,而是这么初始化:
1s := array[i:j]复用带来最大的好处就是避免了内存的重复分配,我们可以在for循环外面声明一个切片,然后重复利用这块空间,每次用完都将其长度置0,这样就需不要每次都去申请空间。还有一种用法,就是多个切片数据是一样,只有开头和结尾不一致,这样就可以在相同数据上,分别按照自己的述求决定起始地址以及长度。 当然,切片这种用法有时也会带来问题。由于不同切片共用空间,其中一个切片改了数据,就很可能会影响到另一个切片的内容。这个在下一节append里面会细讲。
4.nil切片和空切片
1s := []int{} //这是空切片
2var s []int{} //这是nil切片



5.底层实现
这里主要看下make的底层代码,如果读者不感兴趣,可以跳过。
1func makeslice(et *_type, len, cap int) slice {
2 // 根据切片的数据类型,获取切片的容量
3 maxElements := maxSliceCap(et.size)
4 // 比较切片的长度,长度值域应该在[0,maxElements]之间
5 if len < 0 || uintptr(len) > maxElements {
6 panic(errorString("makeslice: len out of range"))
7 }
8 // 比较切片的容量,容量值域应该在[len,maxElements]之间
9 if cap < len || uintptr(cap) > maxElements {
10 panic(errorString("makeslice: cap out of range"))
11 }
12 // 根据切片的容量申请内存
13 p := mallocgc(et.size*uintptr(cap), et, true)
14 // 返回申请好内存的切片的首地址
15 return slice{p, len, cap}
16} 1func makeslice64(et *_type, len64, cap64 int64) slice {
2 len := int(len64)
3 if int64(len) != len64 {
4 panic(errorString("makeslice: len out of range"))
5 }
6
7 cap := int(cap64)
8 if int64(cap) != cap64 {
9 panic(errorString("makeslice: cap out of range"))
10 }
11
12 return makeslice(et, len, cap)
13}append 添加数据
append函数可以为一个切片追加一个元素,至于如何增加、返回的是原切片还是一个新切片、长度和容量如何改变这些细节,append函数都会帮我们自动处理。
1slice = append(slice,10)append的一个例子:
1slice := []int{1, 2, 3, 4, 5}
2newSlice := slice[1:3]
3
4newSlice=append(newSlice,10)
5fmt.Println(newSlice)
6fmt.Println(slice)1[2 3 10]
2[1 2 3 10 5]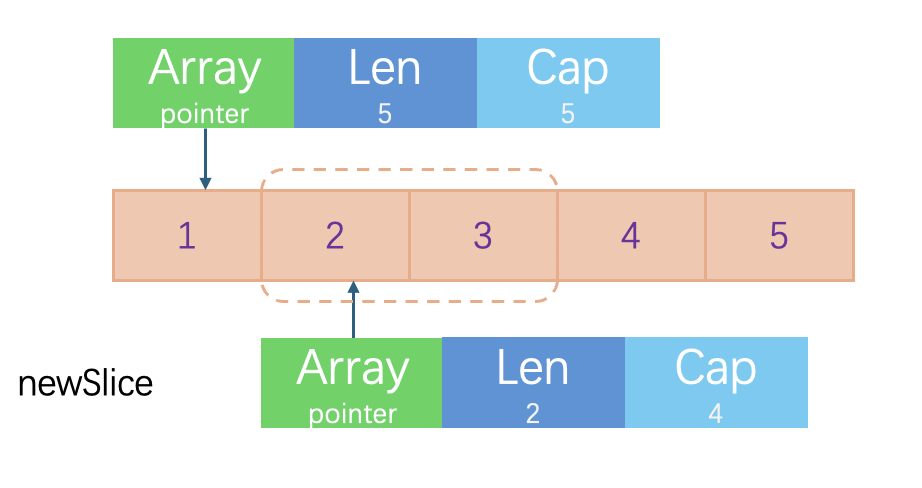
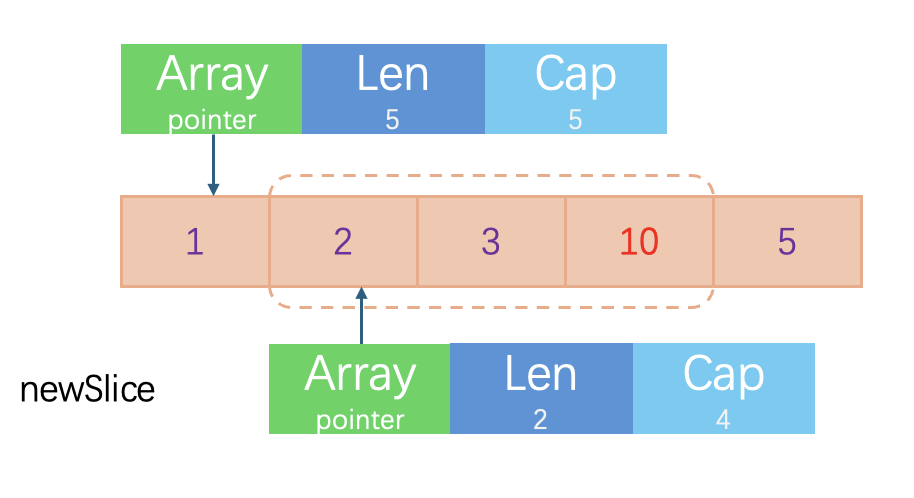
这里要注意的是,我们所说的“newSlice新追加的第3个元素”实际上是相对于newSlice的索引而言,但在底层数组中,它实际上是第4个位置。因此,这次追加操作实际上是将底层数组的第4个元素修改为了10,并将newSlice的长度调整为3。
然而,当append函数发现切片的底层数组没有足够的容量来容纳新的元素时,它会启动扩容策略。这时会创建一个新的底层数组,然后将原数组的值复制到新数组中,并追加新值。在这种情况下,由于新数组与原数组是分开的,所以对新数组的修改不会影响原数组或与之相关的其他切片。
因此,为了避免因共用底层数组而引发的更改原切片的数据,我们在创建新切片时,最好确保新切片的长度和容量相等。这样,在追加操作时,append函数会创建一个新的底层数组,与原数组分离,从而避免了对原数组或相关切片的意外修改。
切片的扩容策略
这一节主要探究golang切片底层扩容策略,不感兴趣的读者亦可跳过。
1func growslice(et *_type, old slice, cap int) slice {
2 if raceenabled {
3 callerpc := getcallerpc(unsafe.Pointer(&et))
4 racereadrangepc(old.array, uintptr(old.len*int(et.size)), callerpc, funcPC(growslice))
5 }
6 if msanenabled {
7 msanread(old.array, uintptr(old.len*int(et.size)))
8 }
9
10 if et.size == 0 {
11 // 如果扩容的容量比原来的容量还要小,这代表要缩容了,那么可以直接报panic了。
12 if cap < old.cap {
13 panic(errorString("growslice: cap out of range"))
14 }
15 // 如果当前切片的大小为0,就新生成一个新的容量的切片返回。
16 return slice{unsafe.Pointer(&zerobase), old.len, cap}
17 }
18
19 // 扩容策略
20 newcap := old.cap
21 doublecap := newcap + newcap
22 if cap > doublecap {
23 newcap = cap
24 } else {
25 if old.len < 1024 {
26 newcap = doublecap
27 } else {
28 // Check 0 < newcap to detect overflow
29 // and prevent an infinite loop.
30 for 0 < newcap && newcap < cap {
31 newcap += newcap / 4
32 }
33 // Set newcap to the requested cap when
34 // the newcap calculation overflowed.
35 if newcap <= 0 {
36 newcap = cap
37 }
38 }
39 }
40
41 // 计算新的切片的容量以及长度。
42 var lenmem, newlenmem, capmem uintptr
43 const ptrSize = unsafe.Sizeof((*byte)(nil))
44 switch et.size {
45 case 1:
46 lenmem = uintptr(old.len)
47 newlenmem = uintptr(cap)
48 capmem = roundupsize(uintptr(newcap))
49 newcap = int(capmem)
50 case ptrSize:
51 lenmem = uintptr(old.len) * ptrSize
52 newlenmem = uintptr(cap) * ptrSize
53 capmem = roundupsize(uintptr(newcap) * ptrSize)
54 newcap = int(capmem / ptrSize)
55 default:
56 lenmem = uintptr(old.len) * et.size
57 newlenmem = uintptr(cap) * et.size
58 capmem = roundupsize(uintptr(newcap) * et.size)
59 newcap = int(capmem / et.size)
60 }
61
62 // 非法值判断,容量确保是在增加,并且容量不超过最大容量
63 if cap < old.cap || uintptr(newcap) > maxSliceCap(et.size) {
64 panic(errorString("growslice: cap out of range"))
65 }
66
67 var p unsafe.Pointer
68 if et.kind&kindNoPointers != 0 {
69 // 在老的切片后面继续扩充容量
70 p = mallocgc(capmem, nil, false)
71 // 将 lenmem 这个多个 bytes 从 old.array地址 拷贝到 p 的地址处
72 memmove(p, old.array, lenmem)
73 // 先将 P 地址加上新的容量得到新切片容量的地址,然后将新切片容量地址后面的 capmem-newlenmem 个 bytes 这块内存初始化。为之后继续 append() 操作腾出空间。
74 memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
75 } else {
76 // 重新申请新的数组给新切片
77 // 重新申请 capmen 这个大的内存地址,并且初始化为0值
78 p = mallocgc(capmem, et, true)
79 if !writeBarrier.enabled {
80 // 如果还不能打开写锁,那么只能把 lenmem 大小的 bytes 字节从 old.array 拷贝到 p 的地址处
81 memmove(p, old.array, lenmem)
82 } else {
83 // 循环拷贝老的切片的值
84 for i := uintptr(0); i < lenmem; i += et.size {
85 typedmemmove(et, add(p, i), add(old.array, i))
86 }
87 }
88 }
89 // 返回最终新切片,容量更新为最新扩容之后的容量
90 return slice{p, old.len, newcap}
91 }- 判断新容量是否大于旧容量的两倍:
如果新申请的容量(cap)大于旧切片容量(old.cap)的两倍,则最终容量(newcap)就是新申请的容量(cap)。否则判断原切片的长度。
2.1. 原切片长度小于1024:
如果旧切片的长度(old.len)小于1024,并且新申请的容量不大于旧容量的两倍,则最终容量(newcap)就是旧容量(old.cap)的两倍,即 newcap = old.cap * 2。
2.2. 原切片长度大于等于1024:
如果旧切片的长度(old.len)大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始,每次增加旧容量的四分之一,即 newcap += newcap / 4,直到最终容量(newcap)大于等于新申请的容量(cap),即 newcap >= cap。 - 容量溢出检查:
在计算最终容量(newcap)时,Go 运行时还会检查是否会发生整数溢出。如果计算出的 newcap 超过了 int 类型的最大值,则最终容量(newcap)将等于新申请的容量(cap)。
这种扩容策略是为了在性能和空间利用之间找到一个平衡点。当切片较小时,通常将容量翻倍,以避免频繁的内存分配和复制操作。但当切片变得非常大时,翻倍扩容可能会导致浪费过多的内存空间,因此采用了逐渐增加的策略。
切片的拷贝(copy)
切片copy的时候只会拷贝目标长度的数据,超过目标长度的不拷贝,注意这里是长度而不是容量
1func main() {
2 slice := []int{1, 2, 3, 4, 5}
3 slice2 := make([]int,0,100)
4 copy(slice2,slice)
5 fmt.Printf("长度为0,数据:%+v,len:%d,cap:%d\n",slice2,len(slice2),cap(slice2))
6 slice3 := make([]int,3)
7 copy(slice3,slice)
8 fmt.Printf("长度不为0,数据:%+v,len:%d,cap:%d\n",slice3,len(slice3),cap(slice3))
9}1长度为0,数据:[],len:0,cap:100
2长度不为0,数据:[1 2 3],len:3,cap:3再看下copy的源代码,不感兴趣,亦可跳过。
1func slicecopy(to, fm slice, width uintptr) int {
2 // 如果源切片或者目标切片有一个长度为0,则直接return
3 if fm.len == 0 || to.len == 0 {
4 return 0
5 }
6 // 记录源切片或者目标切片的长度较小值
7 n := fm.len
8 if to.len < n {
9 n = to.len
10 }
11 // 如果入参为0,也不需要拷贝,直接返回较短的切片长度
12 if width == 0 {
13 return n
14 }
15 // 竞争检测判断
16 if raceenabled {
17 callerpc := getcallerpc(unsafe.Pointer(&to))
18 pc := funcPC(slicecopy)
19 racewriterangepc(to.array, uintptr(n*int(width)), callerpc, pc)
20 racereadrangepc(fm.array, uintptr(n*int(width)), callerpc, pc)
21 }
22 if msanenabled {
23 msanwrite(to.array, uintptr(n*int(width)))
24 msanread(fm.array, uintptr(n*int(width)))
25 }
26
27 size := uintptr(n) * width
28 if size == 1 {
29 d// TODO: is this still worth it with new memmove impl?
30 // 如果只有一个元素,那么直接转换指针即可
31 *(*byte)(to.array) = *(*byte)(fm.array) // known to be a byte pointer
32 } else {
33 // 如果不止一个元素,那么就把 size 个数据 从 fm.array 地址开始,拷贝到 to.array 地址之后
34 memmove(to.array, fm.array, size)
35 }
36 return n
37}切片的遍历
切片是一个集合,我们可以使用 for range 循环来迭代它,打印其中的每个元素以及对应的索引。
1 slice := []int{1, 2, 3, 4, 5}
2 for i,v:=range slice{
3 fmt.Printf("索引:%d,值:%d\n",i,v)
4 }1slice := []int{1, 2, 3, 4, 5}
2for _,v:=range slice{
3 fmt.Printf("值:%d\n",v)
4} 1func main() {
2 s := []int{1,2,3}
3 var wg sync.WaitGroup
4 for _,v := range s {
5 wg.Add(1)
6 go func() {
7 fmt.Printf("%d\n",v)
8 wg.Done()
9 }()
10 }
11 wg.Wait()
12} 1func main() {
2 s := []int{1,2,3}
3 s2 := make([]*int,0)
4 for _,v := range s {
5 s2 = append(s2,&v)
6 }
7 for _,v := range s2 {
8 fmt.Printf("%d\n",*v)
9 }
10}这个问题其实在 C++ 中也同样存在。但真的太容易搞错了,几乎每个 Go 程序员都踩过一遍,而且也非常容易忘记。即使这次记住了,下次很容易又会踩一遍。 甚至知名证书颁发机构 Let’s Encrypt 就踩过一样的坑 bug#1619047。
不过golang1.22版本将要修复这个问题了。
总结
- 切片就是个三元组,多个切片可以共用底层数组。
- append数据时,如果原切片容量足够,则不会新增切片,这个时候就可能会更改原有切片数据。
- for循环遍历切片的问题需要注意只有一个变量存在。